タイトルの通り,3DGANのchainer実装をgithubに上げた.当初はKerasで書いていたが良い結果が得られず,ソースコードの間違い探しをするモチベーションが下がってきたので,思い切ってchainerで書き直した.
実はmnistなどのサンプルレベルのものを超えてちゃんとディープラーニングのタスクに取り組むのは今回が初めてだった.
ChainerによるGANの実装自体は公式のexampleやchainer-gan-libが非常に参考になった. 3DGANはその名の通り3Dモデルを生成するためのGAN(Voxelです).Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modelingで提案されているもの.前回の記事でも触れた. 構造はDCGANと同様で200次元のベクトルよりGeneratorでサンプルを生成,Discriminatorでデータセット由来かGenerator由来か(real/fake)を分類しそのロスをフィードバックする. Generatorは以下の図(論文より引用)のようなネットワークで,Discriminatorはこれを反転したようなモデルになっている.各ネットワーク内では3次元畳み込みを使用する.最適化手法はAdamで,論文ではDiscriminatorがバッチを8割以上正しく分類できた場合はパラメータを更新しないようにしたとあった. データセットにはShapeNet-v2を用いた.このデータセットには様々な種類の3Dモデルが収録されているが,今回は椅子のモデルのみを抽出した.椅子はおよそ6700サンプルが収録されており,ファイル形式は ただ,6700サンプルの3Dデータを全てメモリに乗せることはできなかったため,初期実装では毎回のループで読み込み処理を行っていた.その後, ShapeNet-v2に収録されているデータのサンプルを示す. 3DGANの実装をやろうと決めてから,実験を始める前に3Dモデルの取扱について理解するためのツールをつくっていた.主にはSimple Voxel Viewerで, 64x64x64のボクセルを可視化するため,最初はmatplotlibの3Dplotを試したが, そうして結局,matplotlibの3D volxe plotを採用した.しかしこの関数はまだリリースされていないため(2017/10時点),githubから直接インストールする必要があった.動作も遅いままだが妥協することにした. ネットワークはKerasやTensorflowなどによる実装がいくつかgithubに上がっていたためそれらも参考にしつつ実装した.加えて,有名なGANのベストプラクティスのページを参考にした.ポイントをかいつまむと以下のような感じで実装した. 良さげな感じを出すためにきれいなものを集めた.学習の初期段階ではでたらめなものが出力されるが,徐々に椅子が形成され,50エポックから100エポックくらいでましなものが出来た. 学習の途中では椅子とは独立した無意味なかたまりのオブジェクトが所々に浮かんでいたりしたが,それが消えてくるとかなり見栄えが良くなっていった. ボクセルが全て1になったり0になって消滅したりした.今回幾度も学習をさせてみて,初期の段階からほぼ1なボクセル,あるいはほぼ0なボクセルが生成されたり,規則的なパターン(模様)を持つボクセルが生成されたりすると多くの場合失敗となるという微妙な知見を得た. また,ボクセルが消滅したらその後復活しないこともわかった.ただこれは実装のところで述べたようにロスが間違っているせいかもしれない. また,今回はGANのベストプラクティスの内,以下のトリックは実践しても効果がなかった. 実装に関して,やはりコード自体は 一方で 加えて あとは学習を繰り返すサイクルでは,ハイパーパラメータのチューニングがべらぼうに難しいという印象を受けた.そしてかなり時間がかかる.今回の3DGANではGCP上の Tesla K80 を使ったが1エポックに15分くらいかかった.1回50エポックで試すとしても一晩寝ても終わってない感じ.生成モデルは辛いですね.モデル
3Dモデル
.binvoxが直接収録されていたのでそれを使用した..binvoxファイルのヘッダー読み込みなどが不要であり,処理速度に支障があると感じたので事前に.h5に書き出して使うようにした.



実装
.binvox形式について理解したり,matplotlibでボクセルをどうやってプロットしようかということについて考えていた.scatter plotやsurface plotを使うとマインクラフトのような箱を集積した見映えのプロットが実現できない上,一つ描画するのに数十秒かかることがわかった.そこからまず自作してみようと思いTHREE.jsを使ってSimple Voxel Viewerを作ってみた.ところが結局こっちもいくらか高速化は試したものの,64x64x64のサイズでも密なボクセルになるとメモリーエラーが起こってしまいうまく動作しない問題が起こった.加えて当たり前だがPythonのコードにも組み込めない.zは論文では一様分布だったがガウス分布を使った.Deconv3D+BN+ReLUの繰り返しで,最後だけsigmoid.Conv3D+BN+Leaky-ReLUの繰り返しで,最後だけsigmoid.softplusを使って実装.ただ,実はsigmoid + Adversarial lossがsoftplusと同じなのでDiscriminatorの最後のsigmidは不要なのだが,加えた方がうまくいった(謎).結果
成功例

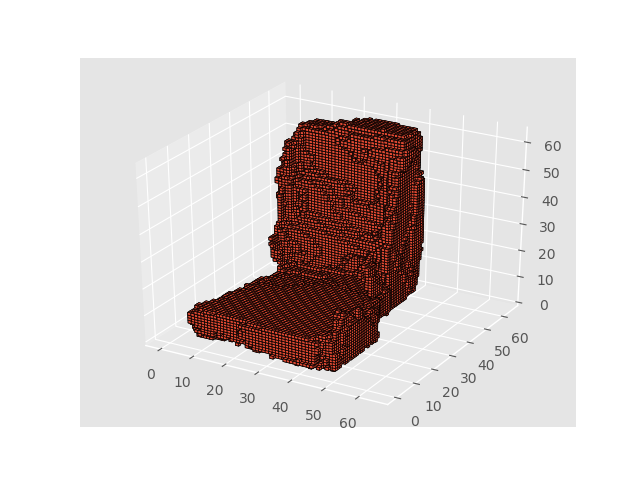


失敗例
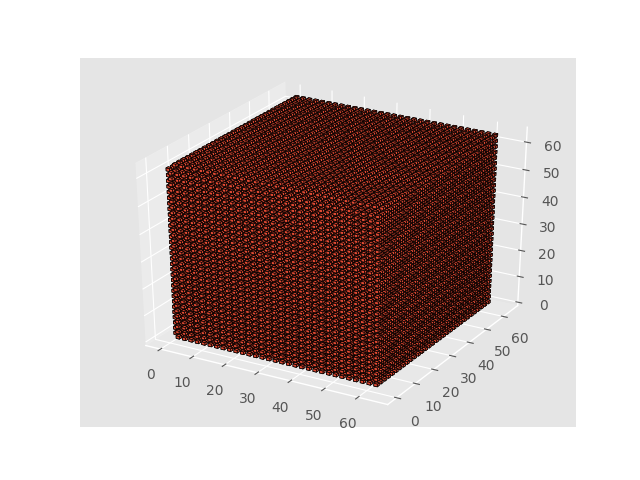
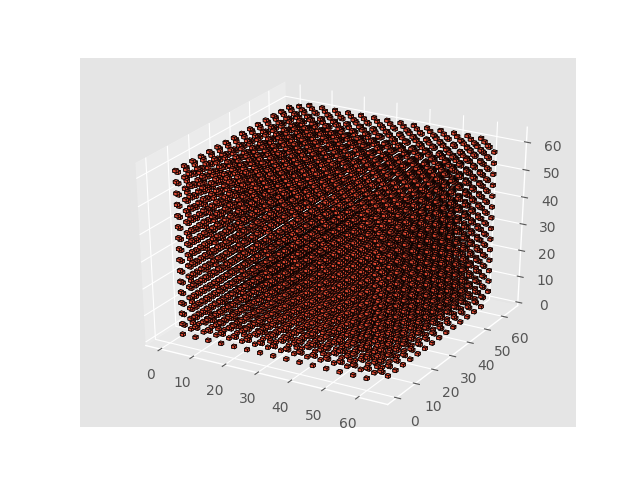
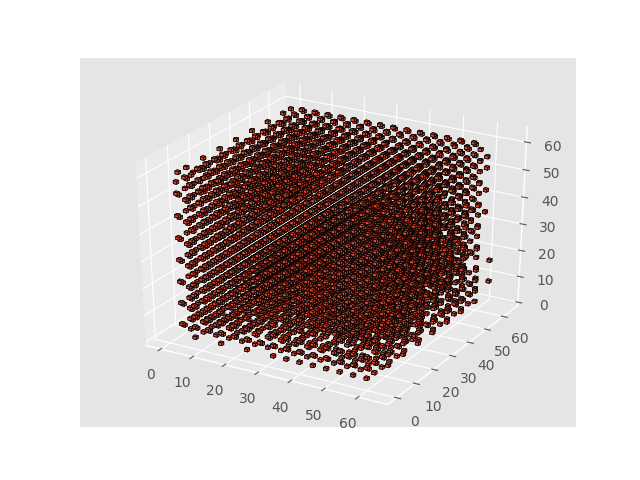
わかったこと
zはガウス分布から取ってきたほうが良さそう.sigmoid + adversarial lossをsoftplusで実装しているので,Discriminatorの最後のsigmoidは不要なはずなのだが,誤って入れていたらうまくいき,外したらうまくいかなくなった.動きゃ勝ちみたいなところがあって釈然としない.Leaky-ReLUをつかう.(項目5)ADAMを使ってDiscriminatorにはSGDを使う.(項目10)Dropoutを使う.(項目17)所感
Kerasの方が圧倒的に簡単にかけるようになっているなと感じた.モデルのインスタンスを作ってバッチをmodel.train_on_batchに渡す処理を繰り返せば良いというイメージでとてもシンプルで良い.DCGANの実装についても,①Descriminatorのみのモデル,②Descriminator(not trainable)+Generatorのモデルをそれぞれ定義することで学習を実現したが,それぞれ独立に学習,更新処理をやるよというのが表現しやすくてわかりやすかった.chainerはまずGPUがある環境とない環境でコードを分けなくてはならず,そこがまず面倒に感じた.自分はリモートマシンが研究室のマシンやGCPなどさまざまなので,手元のmacbookで実装してrsyncでデプロイという形で実装していたので処理をいちいち分岐させるのは面倒に感じた.trainer, updater辺りの構造を理解するのに学習コストが要るなと感じた.extensionもロギングなどよく使う処理をパッケージ化できる所はメリットだと思うが,初めて書く人間にとってはさして複雑でない部分が隠蔽され逆にとっかかりづらいと感じる.慣れてしまえばDCGANの実装もKerasと同じくらいわかりやすくはあったので,忘れないよう継続して使っていきたいと思った.