Batch Normalization
Batch Normalization(BN)は,内部共変量シフトを軽減することで学習を効率化する手法である.特に学習の初期段階において,前段の層の出力分布が変化すると,後段の層はその変化自体に対応する必要がでてくるため,本質的な非線形関数の学習が阻害されてしまうという問題がある.この問題は層を増やせば増やすほど深刻となる.BNは各層の出力をミニバッチごとに正規化することにより分布の変化を抑制する.また重みの初期値への依存度を下げ,正則化を行う効果もある.
具体的には,入力バッチ $\mathcal{B}= {x_1,\cdot\cdot\cdot,x_m }$ に対して
$$\mu_{\mathcal{B}} \leftarrow \frac{1}{m} \sum_{i=0}^{m} x_i$$
$$\sigma^2_{\mathcal{B}} \leftarrow \frac{1}{m}\sum_{i=1}^{m}x_i$$
$$\hat{x}_i \leftarrow \frac{x_i - \mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^2+\epsilon}}$$
$$y_i \leftarrow \gamma\hat{x}_i + \beta$$
のように,標準化を施し,アフィン変換を行う(新たに平均$\beta$と分散$\gamma^2$を与えるとも言える?).この$\beta$と$\gamma$がBNの学習パラメータである.また通常,上記の操作は入力特徴マップのチャネルごとに行う.よってパラメータ$\beta$と$\gamma$は長さチャネル数のベクトルとなる.
Conditional Batch Normalization
Conditional Batch Normalization1(CBN)の”Conditional”の気持ちはクラスラベルをBNのパラメータ$\gamma$と$\beta$に組み込むところにある.どのように組み込むかというと,下図(右)のように両方のパラメータをクラスラベルを基にMLPでモデル化する(だけ).
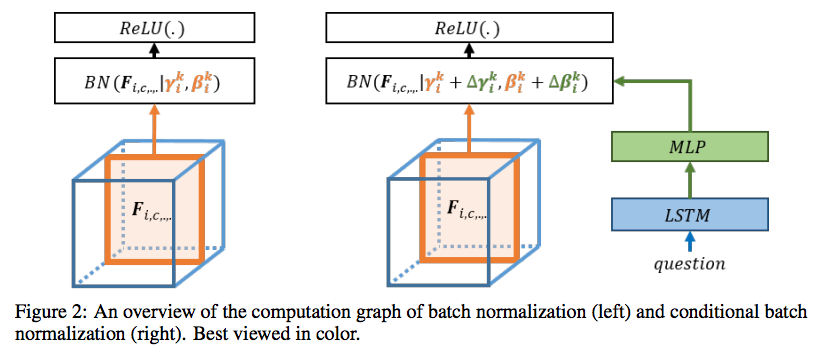
具体的には,入力データのラベルベクトル$c$があったとき,
$$ \Delta\mathcal{B} = MLP(c),\ \ \ \Delta \gamma = MLP(c) $$
のようにクラスラベルをBNのパラメータのチャネル数に合うようにMLPで変換し,
$$ \hat{\beta} = \beta + \Delta\mathcal{B},\ \ \ \hat{\gamma} = \gamma + \Delta\mathcal{\gamma},$$
のように新たなアフィン変換のパラメータとして用いる.引用したCBNの論文では自然言語のembeddingを用いているが,SNGAN2などではクラスラベルの1-of-Kベクタを用いているはず.
なにが嬉しいのか
このあたりが自分もよく把握できていないのが正直なところ.CBN自体は先程触れたSNGANをきっかけに,SAGAN3,BigGAN4でも使われているが,その有無がどれほど精度に影響するのかはあまり言及されていない.おそらく直感的には,従来のような$G$および$D$の最初の層のみにクラスラベルを与えるよりも,様々なレベルの特徴マップに対してクラスラベルを活用するように仕向けることができるのだと思う.
また,各層にクラスラベルを組み込む方法を考えたとき,最もベーシックな方法は1-of-K表現のベクトルを特徴マップのサイズ(FHxFW)に拡大してチャネル方向に結合する手法だが,かなり冗長で,畳み込み演算との相性も微妙と思われる.そういう意味ではCBNを通してクラスラベルを組み込む方が理に適っている可能性はある.
一方,DCGAN5でBNの有効性が示されて以降,GANのgeneratorにBNを用いるのはスタンダードになってきている.そのため,BNをCBNに置き換えたときの計算量の増加,$G$の学習パラメータ増加による学習バランスの悪化が懸念される.
実装
BigGANsのPyTorchによる再現実装にそのコードがあります.標準のBN実装に+αすることでとてもシンプルになっています.
またChainerではSNGANの公式実装でコードがあります.CategoricalConditionalBatchNormalizationという名前になっており,このクラスがConditionalBatchNormalizationクラスを継承するという実装になっているのが若干confusingですが….
所感
実際に研究で使ってみているが,CBN導入で$D$ の学習が早く進みすぎてしまって,モードコラプスになってしまう….もともと$D$が強めで不安定なのだけど,こういう場合に銀の弾がほぼないのが残念.
大体の場合,$D$の学習を遅らせるために,
- $D$の学習率を減らす
- PatchGAN導入している場合,$D$の出力の特徴マップのW, Hを大きくする(層を減らす)
などをして対応するが,かなりケースバイケースなので職人芸感が強くなる….何か知見が溜まったらまた書きたい.
Vries, Harm de et al. “Modulating early visual processing by language.” NIPS (2017). ↩︎
Miyato, Takeru, and Masanori Koyama. “cGANs with projection discriminator.” arXiv preprint arXiv:1802.05637 (2018). ↩︎
Zhang, Han, et al. “Self-Attention Generative Adversarial Networks.” arXiv preprint arXiv:1805.08318 (2018). ↩︎
Brock, Andrew, Jeff Donahue, and Karen Simonyan. “Large scale gan training for high fidelity natural image synthesis.” arXiv preprint arXiv:1809.11096(2018). ↩︎
Radford, Alec, Luke Metz, and Soumith Chintala. “Unsupervised representation learning with deep convolutional generative adversarial networks.” arXiv preprint arXiv:1511.06434 (2015). ↩︎