
DeepMindから出た新たな動画生成GANであるDVDGANを読んだのでまとめました.DVDはDual Video Discriminatorの略です📀
- [1907.06571] Adversarial Video Generation on Complex Datasets
- Adversarial Video Generation on Complex Datasets | OpenReview(ICLR2020投稿中)
TL;DR
- クラスベクトルを用いた条件付き動画生成タスクのGANを提案
- 高解像度で長い動画( $48\times256\times256$ )の生成に成功
- BigGAN1ベースのアーキテクチャを採用
- 計算量の削減を目的に,2つの $\mathcal{D}$ を提案:
- 動画中の画像フレームを評価することに特化した$\mathcal{D}_S$
- 時間的な変化を評価することに特化した $\mathcal{D}_T$
- UCF-101データセットでSOTA
- UCFよりもさらに大きいKinetics-600データセットを使い,様々な動画長・画像サイズでベースラインを提示
Dual Video Discriminator GAN
従来のGANによる動画生成手法は,モデルアーキテクチャ(主にgenerator)に様々な工夫を行っていました.例えば…
- VideoGAN 2: 動画は「動的な前景」と「静的な背景」に分けられるという知識を活用.3DCNNで前景に当たる動画を生成し,2DCNNで1枚の背景を生成して合成する.
- FTGAN 3: 時間的に一貫性を持ったより良い動きを生成するために Optical Flow を活用.VideoGANのアーキテクチャに加えて Optical Flow に条件付けられた動画を生成する.
- MoCoGAN 4: 動画は時間的に不変である「内容」と,各時刻で異なる「動き」の概念に分けられると主張.1動画を生成する際に「内容」の潜在変数は固定しながら,各フレームごとに異なる「動き」の潜在変数を次々とRNNで生成し,それらを結合した$z$から画像フレームを生成する.
などがありました.しかしながら,DVDGANではそのような特別な事前知識を用いず,代わりに「高容量のニューラルネットワークをデータドリブンマナーで学習させる」としており,実質,大量のデータと計算資源で殴る👊と言っています.
ではDVDGANの主な貢献は何かというと,BigGAN1ベースのアーキテクチャを採用し,$\mathcal{D}$ で計算量を削減することで,より大きな動画の生成ができることを示したことだと思います.全体のモデルアーキテクチャは次のようになっています.
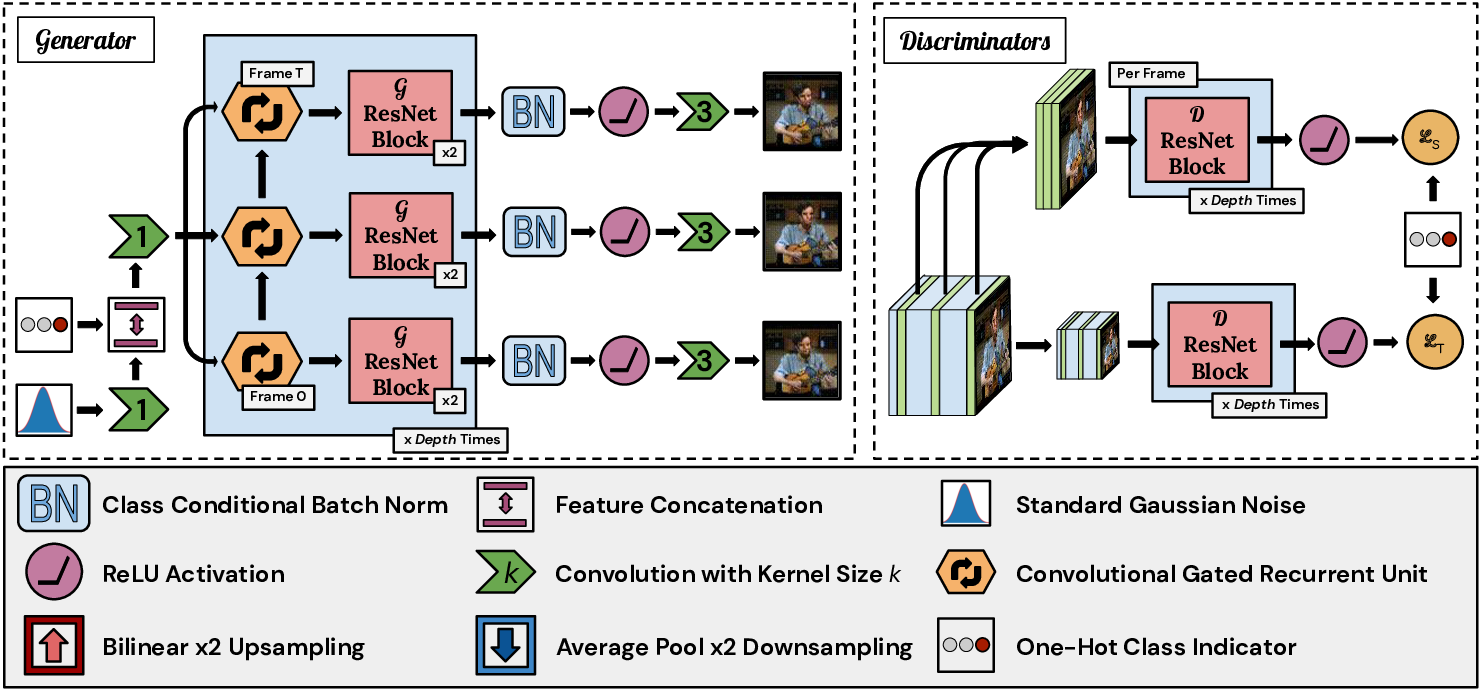
Generator
DVDGANでは動画のクラス情報を使った条件付き動画生成を行います.
まず,正規分布から潜在変数 $z$ をサンプルし,動画のクラスベクトル $y$ のembeddingである $e(y)$ 5と結合します.どちらも120次元のベクトルです.このベクトルを全結合層を用いて$4\times4$の特徴マップに変換します.
その後, Convolutional Gated Recurrent Unit (RNN) 67→ ResNet Block の処理を繰り返し行い(図青の部分),各時刻の画像フレームを生成します.この処理は1度行うと特徴マップの大きさを2倍にするので,例えば$64\times64$ の画像サイズを持つ動画であれば,4回繰り返すこととなります.肝心の動画の時間変化のモデル化はRNNの状態ベクトル $h$ を時間方向に展開することによって学習しています.この展開は特徴マップが最初にRNNを通過するときに1度だけ行われるとのことです.
Discriminator
最初に書いたとおり,2つの $\mathcal{D}$ を持ち,それぞれの役割に基づいて計算量を減らします.
一つは動画中の画像内容の批判に特化した Spatial Discriminator ($\mathcal{D}_S$)(図上)です.2DのResNet Blockで構成されており, 動画からランダムに抜き出した$k$ 個の画像フレームのみ を入力します.
もう一つは時間変化の批判に特化した Temporal Discriminator ($\mathcal{D}_T$)(図下)で,3DのResNet Blockで構成されています.これには動画を入力しますが,すべての画像フレームにダウンサンプリング処理 $\phi(\cdot)$ を適用してから入力します.
時間と空間で担当を分けてしまい,いらない情報は極力削減するということですね.なおそれぞれのハイパラは $k=8$ , $\phi(\cdot)$ は $2\times2$ のaverge poolingが採用されています.これにより, $\mathcal{D}_S$では $8 \times H \times W$ ,$\mathcal{D}_T$ では$T \times \frac{H}{2} \times \frac{W}{2}$ のピクセルを処理する計算になりますが,これは $48 \times 128 \times 128$の動画を 単純に1つの $\mathcal{D}$ で全ピクセル処理するのと比べると59%の削減となります.
ちなみに,$k$ と $\phi(\cdot)$ を決める根拠となった実験も記載されていました. $\phi(\cdot)$ はaverage pooling($4\times4$,$2\times2$),恒等写像,半分の大きさにランダムクロップするの4通りを,$k$ は1, 4, 8, 10 の4通りを検証しています.
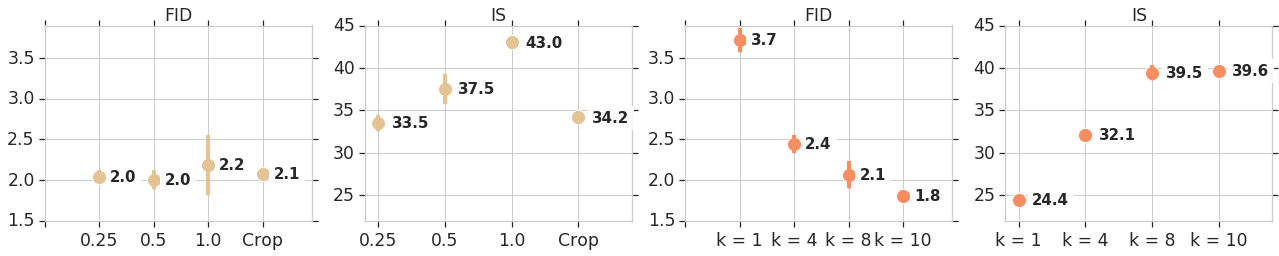
FIDは低いほうが,ISは高いほうがより良い指標です.$\phi(\cdot)$についてはダイレクトにISを劣化させる結果となり,$k$ は8を超えると効果が薄くなることが見て取れますね.
Training settings
GANではモデルに加えてこちらも重要ですが,ほとんどBigGANと同じ…ですかね.ロスには hinge loss 18 を用います. $$ \mathcal{D}: \min _{\mathcal{D}} \underset{x \sim data(x)}{\mathbb{E}}[\rho(1-\mathcal{D}(x))]+\underset{z \sim p(z)}{\mathbb{E}}[\rho(1+\mathcal{D}(\mathcal{G}(z)))], $$
$$ \mathcal{G}: \max _{\mathcal{G}} \underset{z \sim p(z)}{\mathbb{E}}[\mathcal{D}(\mathcal{G}(z))]. $$
その他のトレーニング設定は次のとおりです.
- すべての重みに Spectral Norm9を適用
- 初期化は Orhogonal initialization10
- バッチサイズ 512
- Adam,lrは$G$が $10^{-4}$,$D$ が $5\cdot10^{-4}$
- $\mathcal{G}$ と $\mathcal{D}$ の更新比は 1:2
- $\mathcal{G}$ では $[z; e(y)]$ を用いて class-conditional Batch Normalization を使用
- $\mathcal{D}$ ではprojection discriminator11を使用
Experiment
UCF-101でSOTA
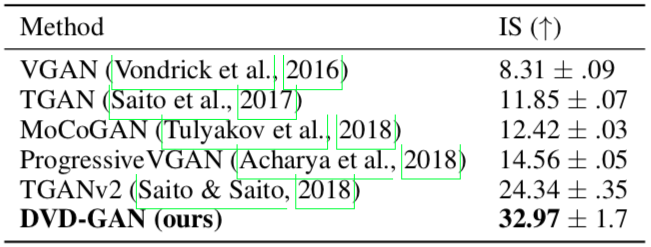
まず,UCF-101データセット12で従来手法と IS(Inception Score)13 で比較をしています.UCF-101は本来は行動認識のためのデータセットですが,動画生成では最もよく用いらます.全101クラス,13320動画で構成されています.
$16\times128\times128$の動画生成で評価した結果,DVDGANのISは32.97とTGANv214 の24.34を大きく上回る精度を見せています.
しかし,appendixで但し書きがされており,DVDGANはそのモデル容量の大きさから部分的に訓練サンプルを記憶している可能性が高いと自ら言っています.その証拠に,サンプルのinterpolation15を行うと,滑らかに変化しない場合があったり,訓練サンプルと酷似したサンプルが生成されたようです.(行ごとに独立,動画の最初の1フレームのみ提示).
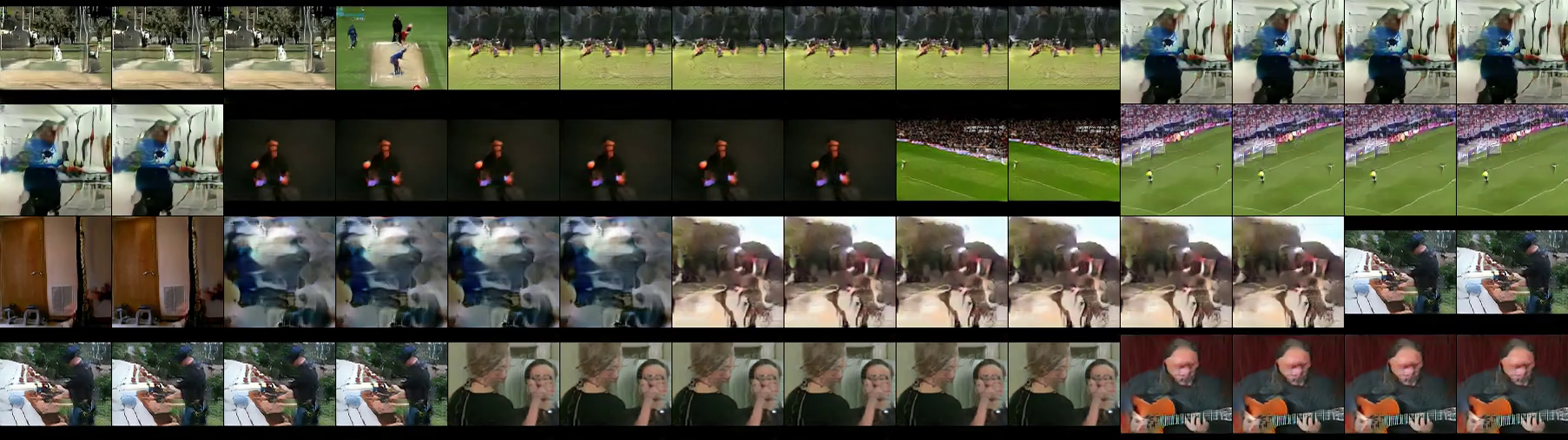
この訓練サンプルの記憶に関し,著者らはInception Scoreという評価指標の欠点であり,同時に,UCF-101は動画生成を検証するのに不十分である(クラス数も各クラス毎のサンプル数も不足している)と指摘しています.
Kinetics-600でベースラインを提示
これを踏まえ,Kinetics-60016と呼ばれるUCF101よりもさらに大きなデータセットでも実験を行っています.これもまた行動認識のデータセットで,全600クラス・およそ50万動画と,UCF-101の6倍のクラス数・40倍のサンプル数を擁しています.各クラスには少なくとも600以上のサンプルが収録されているようです.
このデータセットを使い,論文では今後のベースラインとなるよう様々な解像度・長さの動画でISとFID(Frechet Inception Distance)17 を提示しています.
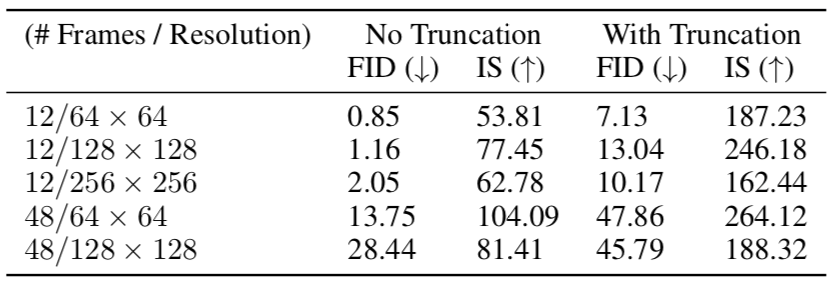
ちなみにWith Truncationの列は,BigGANで提案されたTruncation Trick18と呼ばれるテクニックを用いた場合の最良の値を指しています.
実験の結果から,小さな動画はきれいなテクスチャや構図,動きを持っているが,動画サイズが大きくなるにつれて,一貫性のある物体や動きの生成が困難になると述べられています.しかしながら,$\mathcal{D}_S$ に入力するフレーム数 $k$ を固定した状態で,生成動画の長さを12→48と増やした時,観測できるフレーム数が相対的には減るにも関わらず,同程度に高解像の動画を学習できることがわかったそうです.やはり問題は動きの学習ということでしょうか.
また,Kineticsの場合だとinterpolationもうまくいったそうです.


実際の生成サンプルは下記リンクに上がっています.
私個人の印象としては,画像はきれいなのですがやはり動きがまだ不自然だと思いました.風景画は良いですが,人や物が絡むと剛体運動をしていない(物自体の形が不自然に変わる)のが気になります.
ちなみに学習は 32〜512 TPU pods でおよそ12〜96時間 とのことです😰
実験の章ではさらに動画予測にDVDGANを拡張して実験を行っていますが,これについては割愛します(すいません).
所感
特別な事前知識を使わずにデータで殴るのは正しいと思う.ただ,ここまで大規模なデータでも不自然になるということは,動きをうまく学習できる機構は未だ存在していないと言わざるを得ないと思います.
$ \mathcal{D}$ を複数にして,空間と時間で担当を分けるという発想はこれが初めてではない.実際,MoCoGANも全く同様に2つの $\mathcal{D}$ を提案しており(DVDGANの $k=1$ , $\phi(\cdot)$ が恒等写像である場合に相当する),こうすることで学習の収束が早まると指摘している.そういった意味でも,DVDGANはアーキテクチャの工夫というよりはむしろ,計算量の削減に注力したと言えます.
現在の動画生成では計算量と精度に関するトレードオフを評価する慣習はないので,計算量を削減しながらSOTAを更新しているのはすごい.もちろん計算量の削減なしには現実的に難しいこともあるが,単純にスコアを上げるだけならまだ余裕があるように見える.
$\mathcal{D}$ の$k$や$\phi$のチューニングに関する実験結果は,FIDは時間的な劣化に疎く,ISは空間的な劣化に疎い,というようにも解釈できる.いずれにしても,ISやFIDが動画の品質を正しく評価できているかは微妙だなぁという実感は日頃からあるので,主観評価もあったらなお良かった気がします.
A. Brock+, 2019, “Large Scale GAN Training for High Fidelity Natural Image Synthesis”, https://arxiv.org/abs/1809.11096 ↩︎
C. Vondrick+, 2016, “Generating Videos with Scene Dynamics”, https://arxiv.org/abs/1609.02612 ↩︎
K. Ohnishi+, 2018, “Hierarchical Video Generation from Orthogonal Information: Optical Flow and Texture”, https://arxiv.org/abs/1711.09618 ↩︎
S. Tulyakov+, 2018, “MoCoGAN: Decomposing Motion and Content for Video Generation”, https://arxiv.org/abs/1707.04993 ↩︎
論文中では “a learned linear embedding $e(y)$ of the desired class $y$. “と表記されていますが,詳細は1にあるのでしょうか….おそらくですが,クラスを単純な1-of-Kの符号化ではなく,より近い概念であれば近くなるように符号化したい意図があると思います. ↩︎
N. Ballas+, 2015, “Delving Deeper into Convolutional Networks for Learning Video Representations”, https://arxiv.org/abs/1511.06432 ↩︎
I. Sutskever+, 2011, “Generating Text with Recurrent Neural Networks”, https://www.cs.utoronto.ca/~ilya/pubs/2011/LANG-RNN.pdf ↩︎
J. Hyun+, 2017, “Geometric GAN”, https://arxiv.org/abs/1705.02894 ↩︎
T. Miyato+, 2018, “Spectral Normalization for Generative Adversarial Networks”, https://arxiv.org/abs/1802.05957 ↩︎
AM. Saxe+, 2013, “Exact solutions to the nonlinear dynamics of learning in deep linear neural networks “, https://arxiv.org/abs/1312.6120 ↩︎
T. Miyato, 2018, “cGANs with Projection Discriminator”, https://arxiv.org/abs/1802.05637 ↩︎
UCF101 - Action Recognition Data Set, https://www.crcv.ucf.edu/data/UCF101.php ↩︎
T. Salimans+, 2016, “Improved Techniques for Training GANs”, https://arxiv.org/abs/1606.03498 ↩︎
M. Saito+, 2018, TGANv2: Efficient Training of Large Models for Video Generation with Multiple Subsampling Layers, https://arxiv.org/abs/1811.09245 ↩︎
GAN界隈では,2点の潜在ベクトルの内挿を線形補間などで行い,順にgeneratorで生成してその変化を観測することを指す. ↩︎
Kinetics - DeepMind, https://deepmind.com/research/open-source/kinetics ↩︎
M. Heusel+, 2017, “GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium”, https://arxiv.org/abs/1706.08500 ↩︎
正規分布の裾の方から取った潜在ベクトルは見た目や構造が崩れたサンプルになりやすいことから,そういった潜在ベクトルを棄却することで,多様性(diversity)を少々犠牲にしつつも本物らしさ(fidelity)を確保しようというテクニック.より正確には1を参照. ↩︎